PROBLEM:
In STATUS >> DEVICES bottom right pane, if your test results have a triangle with an exclamation point inside of it displayed next to them, then this indicates that the results are old/stale and have not been written to the database recently.
Technically speaking, a stale result indicates that the test poll value has not been written to the database in at least 3 poll cycles. e.g. A test with a 5 minute poll interval that has not written a test result in at least 16 minutes will display as stale.
SOLUTION:
The most likely causes of stale results are usually caused by:
a) BVE/DGE/DGEx's server times are not synchronized.
b) A table in the MySQL database, on the monitoring/upstream DGE, needs repairing or the database needs to be optimized.
c) DGEx is unable to connect to the upstream DGE.
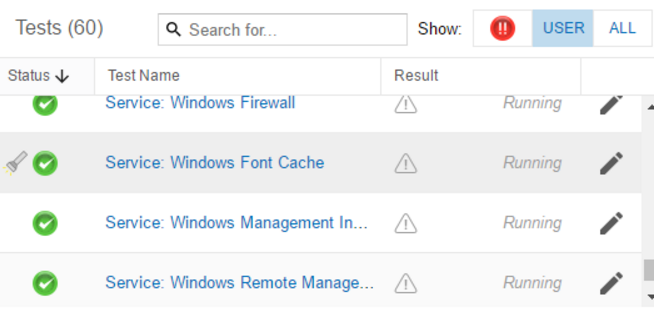
Please check the following:
(A) BVE/DGE/DGEx's server times are not synchronized
If the time-offsets are significant, results may not be processed as expected or in a timely manner.
* Check SUPERUSER >> HEALTH
* If you see any Time offsets in SUPERUSER >> HEALTH, please correct as per Traverse Component Health Page Shows Non-Zero Time Offsets
(B) A table in the MySQL database, on the monitoring/upstream DGE, needs repairing or the database needs to be optimized
* Check the test "Writer Queue size" for the DGE monitoring the device with 'Stale Results'. The 'Writer Queue Size (AggregatedDataDbWriter0)' test is expected to be historically high compared to normal, which could point to a database repair/optimize being required.
* Check <TraverseHome>\logs\mysql.log and see if it has entries containing:
Table 'XXXXX' is marked as crashed and last (automatic?) repair failed
If it does, it will require a database repair, followed by an optimize.
* Check if either the BVE or DGE that is monitoring these 'Stale Results' requires a repair:
cd C:\Program Files (x86)\Traverse\utils
db_optimize.pl --info
Scroll to the very top and if you see the below, the database requires a repair:
"Table 'XXXXX' is marked as crashed and last (automatic?) repair failed"
If the above output is not visible (due to too many lines outputted). Then you can pipe the output to a file
db_optimize.pl --info >> output.txt
If a repair is required, please follow How Do I Repair An Error With A Traverse Database followed by an Optimize Tip: How Do I optimize the DGE Database.
Bear in mind that this may take several hours to complete. It is advised to tail the database_repair.log in a separate command prompt so you can confirm it's running. The full list of Windows commands are repeated below for your convenience.
On the affected DGE:
1) Stop all Traverse services
2) Run the database repair
cd <TraverseHome>\utils
db_repair.cmd
Tail the database_repair.log in a separate window to see the progress of the repair:
cd <TraverseHome>\logs
tail -f database_repair.log
* If a repair was carried out, then an optimize will be required afterwards. Even if a repair was not required, running a db_optimize would be advisable, especially if "Writer Queue size" test on the DGE is high, as this is an indicator of a non-optimized database. It will complete immediately if it was not required. Tip: How Do I Optimize The DGE Database. This can also possibly take several hours.
3) Once the repair finishes (the cursor returns)
Start all Services
4) Run a database optimization
cd <TraverseHome>\utils
db_optimize.pl --run
Once the repair/optimize has completed, it will take time for the backlog of results to be written to the database. Take note that DGEx's can store up to 12 hours of results and will write the oldest results to the database first. It can take some time for these test results to 'catch up'.
To confirm that the results are now being written to the database:
1) Navigate to STATUS >> DEVICES
2) Click on the 'Blue URL' device name
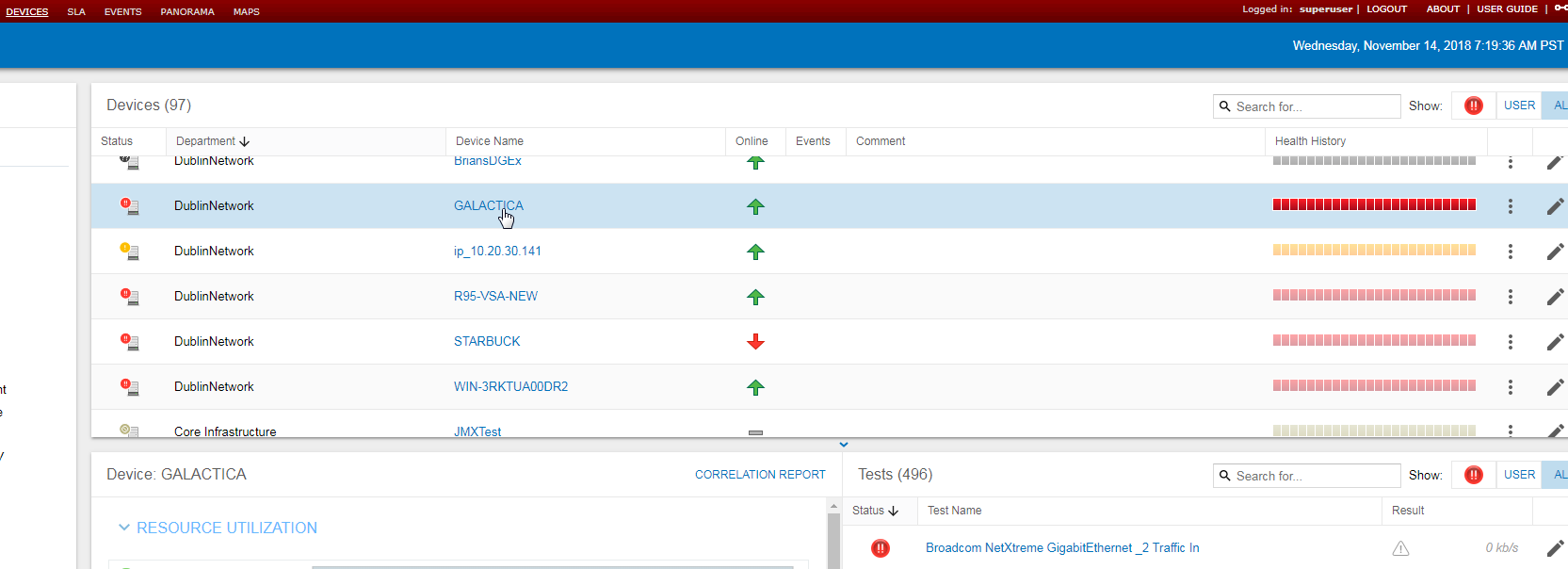
3) This page will display the timestamp of the most recently written test result for
each individual test. Hitting refresh occasionally, you should start to see the
timestamps of the tests advance to within a polling cycle of the current time.

(C) DGEx is unable to connect to the upstream DGE
Please log onto the monitoring DGEx and check the current date error log located at
* <TraverseHome>\logs\monitor\error-20yy-mm-dd.log
and look for any entries of the below:
* (WARN) Unable to communicate with upstream DGE; Results will be stored locally while attempting to restore connection
If the DGEx has lost connectivity, please ensure that all the required ports are open on the firewall. Port 9443 is responsible for forwarding test results to the upstream DGE so please confirm that it is open as per the below articles:
Communication between Traverse servers
Using Traverse Behind Firewalls
If the DGEx is constantly dropping and reconnecting to the upstream DGE, this would usually indicate a networking issue between the DGE and the DGEx. It is advisable to investigate and resolve this networking issue to ensure Traverse stability.
Once you have corrected the DGEx to DGE connectivity issue, then as with (b), please review STATUS >> DEVICES to confirm that results are catching up.